|


| |
О.И. Подгорная
д.биол.н., вед. н. с. Института цитологии РАН, доц. СПбГУ
БЛЕСК
И НИЩЕТА ПРОГРАММЫ
«ГЕНОМ ЧЕЛОВЕКА»
В
1988 г. по инициативе американских ученых У. Гилберта и Дж. Уотсона была создана
международная организация «Геном человека», ставящая целью координацию работ по
определению полной нуклеотидной последовательности всей ДНК человека.
В
основе программы лежит деятельность Джеймса Уотсона, который вместе с Фрэнсисом
Криком и М. Уилкинсом в 1962 г. получил Нобелевскую премию за открытие двойной
спирали ДНК. Став Нобелевским лауреатом, Ф. Крик решил продолжить свою научную
деятельность и сделал еще несколько интересных открытий. Сейчас он пытается
понять, как работает мозг.
Уотсон же решил стать научным администратором. Построив один из лучших
биологических институтов мира «Cold Spring Harbor», он организовал программу
«геном человека». О начале работ по расшифровке (секвенированию) генома Уотсон
объявил в 1988 г., а в 1990 г. — был основан Международный консорциум по
секвенированию генома человека.
Геном
человека — это около 3,3 миллиардов нуклеотидных звеньев — букв генома,
распределенных между 23 парами хромосом в ядре; всего около двух метров ДНК в
каждой клетке. Идея программы состояла в том, чтобы мобилизовать лучшие
интеллектуальные силы для того, чтобы читать геном подряд — по «буквам». Задача
казалась грандиозной до невыполнимости. Если даже геном и не прочтут, то
появятся новые технологии, новые ошеломляющие результаты подобно тому, как это
произошло при разработке атомной бомбы. Казалось, что много лет студенты-биологи
всех университетов в России и в мире, все следующее поколение биологов будут,
как негры, клонировать и секвенировать фрагменты ДНК. Больше ни на что ни
времени, ни сил у ученых, стиснутых рамками этой программы, не останется.
Благодаря огромному научному авторитету Уотсона, удалось так организовать
работу, что результаты исследователей разных стран по клонированию и
секвенированию не пропадали, а включались в международную базу данных.
Стало
невозможным опубликовать статью, если представленная в ней последовательность не
находится в этой базе данных, абсолютно доступной для всех. Такая постановка
вопроса привела не к конкуренции, а к интеграции; научные сотрудники стали
работать вместе.
В
том, что геном человека был прочитан на удивление быстро, особенно велика роль
японцев. В 1987 году, через десять лет после появления технологии определения
последовательности ДНК, японцы придумали автоматический секвенатор, а в 1998
году построили автоматический высокопроизводительный капиллярный секвенатор ДНК,
что повысило уровень всего проекта. Появилась надежда, что с секвенированием
вручную покончено. Наряду с международным консорицумом Уотсона в США появилась
«фабрика» с автоматическими секвенаторами, организованная Вентером Крейгом на
деньги фармацевтических компаний. В результате ее работы геном был прочитан к
февралю 2001 года. Вентер попытался сделать проект коммерческим, но эта идея
встретила категорическое противодействие научного сообщества, несмотря на
уважение западного мира к правам на интеллектуальную собственность. В результате
компромисса результаты расшифровки генома и их анализ были опубликованы в двух
престижных научных журналах Nature и Science одновременно [1, 2]. При подобных
публикациях ни о каком коммерческом использовании результатов, то есть
закрытости данных по геному, речь не идет.
Технологические надежды программы оправдались: построены фабрики, использующие
компьютерные и молекулярно-биологические технологии. Но как бы ни был хорош
методический подход, с помощью которого прочитан геном, предметом публикаций
является анализ полученных данных.
Последовательности в геноме человека
Для
того, чтобы прочесть эту базу данных, посмотрим, какие последовательности ДНК
вообще встречаются в геномах.
Структурные
гены
Центральная догма молекулярной биологии гласит, что в процессе реализации
наследственной информации текст, записанный в молекуле ДНК на одном языке
(четырехбуквенным кодом нуклеотидов), переводится на язык белков (двадцатибуквенный
код аминокислот). Тексту, написанному на одном языке (нуклеотиды) строго и
однозначно соответствует другой текст (аминокислоты в белке). Информация в
процессе транскрипции переписывается с ДНК на РНК, а затем переводится в белок в
соответствии с генетическим кодом (рис. 1, 1).
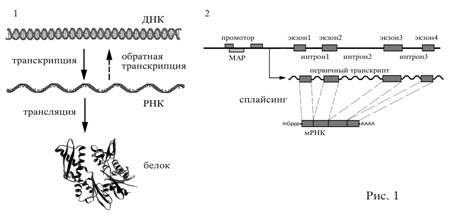
Рис.1.
1. Схема реализации наследственной информации реализуется в процессе
транкрипции и трансляции. 2. Структура человека. После синтеза РНК из нее
удаляются интроны.
Структурные гены кодируют белки.
Самое
поразительное открытие программы — в геноме человека очень мало генов.
Ожидалось, что обнаружится не меньше ста тысяч генов. По окончании тотального
секвенирования, разные компьютерные программы дают оценки от 21 до 39 тысяч
(можно задавать критерии c разной степенью строгости). Одна из лучших программ
насчитала 26688 генов. Точное количество структурных генов, кодирующих белки, до
сих пор не известно. Сейчас принято считать, что в геноме может поместиться
около 30000 генов.
Белков же у человека гораздо больше, чем генов — около 150 тысяч. Самое большое
разнообразие белков — в нервной ткани и в половых клетках. Почему же белков в
пять раз больше? Во-первых, белок — это не только цепочка аминокислот,
образующаяся при трансляции. Белки включают и другие компоненты: углеводы,
липиды, молекулы пигментов и производных витаминов, ионы металлов. При
образовании функционально активных белков часто посттрансляционные модификации
меняют исходную цепочку аминокислот до неузнаваемости. Во-вторых, с одного гена
может синтезироваться несколько различных белковых продуктов. Есть много
случаев, когда синтезированная в клетке белковая молекула разрезается на
короткие фрагменты, которые функционируют как гормоны или ферменты. Например, в
гипофизе человека из одного гена образуется шесть гормонов и два нейрорегулятора
— бета-эндорфин и мет-энкефалин. Кроме того, альтернативный сплайсинг, который
поначалу посчитали просто игрой природы, оказывается мощным фактором увеличения
разнообразия белков. По оценкам специалистов, более половины генных продуктов
подвергаются альтернативному сплайсингу. Легко представить, что количество
возможных вариантов белков значительно возрастает. Результирующее множество
белков называют протеомом.
После
завершения геномного проекта первейшая задача — разобраться в хаосе уже открытых
белковых продуктов (каталогизация белков). Изучение многообразия белков в
постгеномную эру выливается в становление новой науки — протеомики (по аналогии
с геномикой). В 2001 году создана международная организация по изучению протеома
человека. Время открытий в области протеомики еще впереди. Обратимся к
последовательностям ДНК генома.
Гены
имеют сложную структуру: кроме кодирующих белок участков — экзонов, они содержат
некодирующие интроны. Причем некодирующие фрагменты — интроны и регуляторные
области составляют большую часть гена. Абсолютным чемпионом по количеству
экзонов оказался ген белка мышечной ткани титина, у которого было насчитано 234
экзона. При транскрипции гена экзоны и интроны считываются вместе как одна
большая молекула РНК, после чего в процессе сплайсинга интроны вырезаются, а
экзоны сшиваются. Собственно, только экзонная часть гена имеет свое проявление в
белке (рис.1, 2).
У
каждого структурного гена имеется большой регуляторный район, содержащий ряд
различных последовательностей, например, для посадки фермента РНК-полимеразы,
связывания транскрипционных факторов и много другого. Один из таких участков
называется матрикс-ассоциированный район (МАР). Согласно современным
представлениям, ген может считываться РНК-полимеразой, только если он к чему-то
прикреплен. Как правило МАР расположены в промоторных областях и, реже, в
интронах генов (рис. 1, 2).
Итак,
общее количество генов — около 30000. Со всеми экзонами и интронами,
промоторными районами и другими обслуживающими транскрипцию
последовательностями, все это вместе занимает около 5% генома. Если считать
только то, из чего получается белок (не считая интроны, промоторы), получается
1% генома. Один! И 99% ДНК генома не имеют никакого выражения в белке. В
основном это повторяющаяся ДНК.
Различают несколько классов повторяющейся ДНК. Основные два класса — тандемные и
диспергированные повторы (рис. 2).
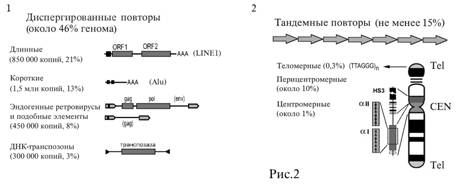
Рис.2.
1. Основные классы диспергированных повторов человека. 2. Тандемные повторы.
Их положение на хромосоме.
Диспергированные
повторы
В
геноме человека они занимают не менее 46%. В геноме они обнаруживаются
повсеместно, поэтому называются «диспергированными» (т.е. рассеянными). Одна
группа диспергированных повторов — ДНК-транспозоны, перемещающиеся без участия
РНК, по механизму «вырезать-вставить». Остальные распространяются по геному при
участии РНК — ретропозоны. Механизм их расселения по геному при помощи обратной
транскрипции (рис.2, 1) называют ретропозицией по механизму
«копировать—вставить». Он также характерен для большой группы ретровирусов.
Самый известный ретровирус — вирус иммунодефицита человека (ВИЧ). Около 200
тысяч ретровирусов геном человека носит с собой как «кейс с наручниками». У нас
есть и собственные, эндогенные вирусы. Со своими эндогенными ретровирусами
человек рождается, умирает. Значение их для хозяйского организма все еще
остается загадкой.
Больше трети человеческого генома занимают два самых успешных класса ДНК —
длинные и короткие и длинные рассеянные повторы. Длинные диспергированные
повторы (у человека самый распространенный это LINE1, 17% генома, рис.2, 1)
интересны тем, что при анализе их ДНК были найдены две открытые рамки
считывания. Экспериментально выделили соответствующие белки. Оба белка обладают
свойствами, необходимыми для ретропозиции. С длинного повтора считывается РНК;
которая обратно транскрибируется, то есть на ней синтезируется ДНК. ДНК-копия
при помощи белков встраивается в геном в новом месте. Короткие диспергированные
повторы (у человека преобладает семейство Alu-повторов, 11% генома) тоже
встречаются повсеместно, в том числе в интронах и регуляторных областях генов.
Они ничего не кодируют, у них нет ORF. В отношении транспозиции короткие повторы
несамостоятельны. Они используют белки, кодируемые длинными повторами. Из пары
LINE1-Alu получился очень эффективный вектор для встраивания чужеродных
фрагментов ДНК в геном.
В
геноме человека было обнаружено более полутора миллионов коротких и около 900
тысяч длинных рассеянных повторов. Но среди них оказалось мало активных,
способных к ретропозиции элементов. Очевидно, что их размножение в геноме сильно
подавлено. При одновременной ретропозиции миллионов копий коротких повторов,
геном просто прекратил бы свое существование. Тем не менее, зафиксировано
несколько десятков случаев активной транспозиции, происходящей и в наши дни,
например, в медицинской генетике, в культуре клеток и на модельных системах.
После
опубликования в 2002 году генома мыши стали возможны некоторые сравнения [3]. И
у человека, и у мыши обнаружилась строгая корреляция: там, где много генов,
много и коротких диспергированных повторов; там, где мало генов — много длинных
диспергированных повторов. При том, что их функции в геноме неизвестны, можно
предположить, что короткие повторы помогали при расстановке генов и организации
их экзон-интронной структуры.
Тандемные
повторы
Тандемные повторы — один из первых изученных классов ДНК. На них отрабатывались
тривиальные теперь приемы генной инженерии. Определение «тандемный» означает,
что эти последовательности устроены из очень простых, относительно небольших
последовательностей, уложенных тандемно — «голова к хвосту». К тандемным
повторам относятся теломерные и сателлитные ДНК.
Структура всех хромосом принципиально одинакова: два плеча, посередине первичная
перетяжка — центромера; на концах теломеры (рис. 2, 2). Теломерные ДНК занимают
фиксированную позицию на самом конце хромосомы, в области теломеры, и
ограничивают ее, не давая ей слиться с другими. Теломерный повтор очень
консервативен. Практически у всего живого царства он устроен одинаково.
Название «сателлитная ДНК» (сатДНК) — результат исторического курьеза. Название
дали по первому способу выделения. Ничьим эта ДНК спутником не является, но
название прижилось. Устроена она принципиально так же, как и теломерная ДНК. Но
в отличие от эволюционно консервативных теломер сателлиты вариабельны до такой
степени, что могут быть систематическим признаком, то есть они видоспецифичны.
Более того — внутри вида существуют хромосомоспецифичные варианты сатДНК. У
человека можно различить самые разнообразные классы сатДНК. Зато ее положение на
хромосоме стабильно. Из нее состоит центромерный район и большие поля сатДНК его
окружают, подстилают. Сходным образом огромные поля сатДНК подстилают концы
хромосом, где находятся теломерные повторы. Встречаются отдельные вставки сатДНК
и на плечах хромосом, между теломерами и центромерой.
Тандемные повторы играют важнейшую роль в самом существовании хромосом. Любая
хромосома должна быть отграничена от остального генетического материала (это
обеспечивается уникальными свойствами теломерной ДНК) и должна нормально
наследоваться, правильно «растаскиваться», при делении клетки (центромерная
ДНК). Без клонированных теломерных и центромерных участков невозможно и создание
искусственных хромосом, необходимых для манипуляций с генами.
Авторы программы «Геном человека» в первых публикациях старались не
акцентировать тот факт, что их геном далеко не полон. Но когда были представлены
результаты секвенирования генома мыши, подчеркивалось, что полученные данные
«представляют собой 96% эухроматической части генома» и не более того. Что же
такое эухроматическая часть генома?
Полуторавековые исследования клеточного ядра создали представление о том, что
плотно упакованная в хромосомы ДНК после деления клетки разворачивается в
рабочее состояние. Развернутые хромосомы в ядре клетки называют хроматином. Но
разворачиваются хромосомы не полностью. Два метра развернутой ДНК в ядро клетки
не влезут. Ту часть, которая разворачивается и на которой происходит активный
синтез РНК, назвали эухроматином (настоящим хроматином). Районы хроматина,
которые остаются почти такими же компактными, как в хромосоме, называются
гетерохроматином. Сюда относятся прицентромерные и прителомерные части хромосом.
Гетерохроматиновые районы хромосом не прочитаны при выполнении программ «Геном
человека» и «Геном мыши».
Технология чтения ДНК разрабатывалась для генов, с которых транскрибируется РНК,
имеющая выражение в белке. С помощью этих методов можно заполнить довольно
длинные разрывы между генами, но невозможно прочесть и положить на карту
хромосомы огромные поля почти одинаковых тандемных повторов, которые в
большинстве клеток не транскрибируются. В рамках традиционного подхода
невозможно даже определить размер таких блоков. Центромерные и прителомерные
районы представляют собой «белые пятна» на картах хромосом человека и мыши.
Часть генома, организация которой еще неизвестна, весьма велика — это десятки
процентов.
Понятно, что в прочитанной части генома встретятся структурные гены,
разбросанные повторы разных классов, а представленность тандемных повторов
окажется заниженной. Пока нет надежных подходов для распознавания генов,
продуктом которых является только РНК, — транскрибируемых, но не транслируемых.
В части генома без генов около 40% занимают повторяющиеся последовательности
разных типов, которые можно распознать. А вот еще 20% — это последовательности,
которые никто никогда не клонировал, не секвенировал. Они расположены в так
называемых генных пустынях — огромных пространствах вдоль плеч хромосом, где
вообще нет генов. Что это такое — никому не известно и не понятно. Еще одно
свидетельство нашего невежества и, вероятно, неверной установки, положенной в
основу программы «Геном»: прочесть все гены, которые там находятся.
Слово
«геном» придумали раньше, чем стало известно о нем что-либо определенное. Геном
незаслуженно носит свое название, по крайней мере у человека. Он вовсе не
представляет совокупность генов, как можно подумать (по аналогии с протеомом —
совокупностью всех белков организма). Теперь мы знаем, какой ничтожный процент
занимают в геноме классические кодирующие последовательности. Существующие
парадигмы: «от гена к признаку», «один ген—один белок», «наследственная
информация реализуется в процессе синтеза белка» не предполагают наличия того
количества некодирующей ДНК в геноме, которая там оказалась.
Как
это часто случается в науке — не удалось «доказать, что апельсин — это веничек
для сбивания сметаны. Зато сколько интересного мы узнали по дороге!» [4].
Сравнительная геномика
После того, как в мире построено несколько фабрик, круглые сутки считывающих
нуклеотиды, стало возможным организовать дочерние от «генома человека»программы.
В результате уже через год был опубликован геном мыши. Сейчас в процессе
прочтения находятся геномы многих организмов.
К
началу 2000 года полностью расшифрованы геномы ряда многоклеточных (плодовой
мухи дрозофилы, цветкового растения арабидопсиса) и одноклеточных организмов
(около 300 разных видов бактерий). Прочитан геном кишечной палочки и пекарских
дрожжей. Завершены геном круглого червя ценорабдитис, сельско-хозяйственной
культуры риса; продолжаются проекты по расшифровке генома собаки, курицы,
аквариумной рыбы данио и рыбы фугу. Обсуждаются такие проекты как чтение генома
кишечнополостного животного гидры и низшего хордового — асцидии. Так на наших
глазах возникает новая наука геномика, или точная зоология, которая позволит
выявить закономерности эволюции геномов. Понадобится время, чтобы довести до
конца чтение геномов животных, находящихся в ключевых точках эволюционного
дерева, а еще больше времени понадобится, чтобы осознать и привести в порядок
полученные данные.
Некоторые эволюционные закономерности оказалось возможным увидеть и на двух
геномах. Значительная часть генома человека является результатом сегментных
дупликаций. На разных хромосомах можно обнаружить куски, очень похожие друг на
друга. Вообще, природа часто использует механизм дупликации. Это основной
механизм новообразований в эволюции. Сначала посредством дупликации создается
«мраморная глыба» а затем посредством мутаций глыба «обтачивается» под
необходимые функции.
90%
геномов мыши и человека могут быть разделены на одинаковые «синтеничные» районы
(synteny — дословно «одна нить»). Синтеничные районы отражают происхождение мыши
и человека от одного предка. Порядок генов в них одинаковый. Одни и те же районы
у человека и мыши расположены на разных хромосомах, но отчетливо распознаваемы.
При этом часто сохраняется не только консервативный порядок генов, но и
расстояние между ними (!), заполненное видоспецифичными повторами. Несмотря на
то, что короткие ретропозоновые повторы у человека и мыши различаются по
последовательности и длине, их позиции закреплены. Недостаток длины повтора мыши
компенсируется количеством повторов. Видимо, в эволюции разрешены перестановки
больших кусков хромосом, но запрещено перемещение генов в пределах синтеничного
района, минимальный размер которого пока еще не определен.
Специфической чертой человека и высших обезьян является то, что около 40 млн.
лет назад в их геноме произошло бурное расселение короткого повтора Alu. Затем
активность мобильных элементов в родословной наших предков неуклонно падала.
Теперь в геноме человека активно лишь несколько семейств транспозонов: длинные
диспергированные повторы LINE1, только одно небольшое подсемейство Alu и
несколько групп эндогенных ретровирусов. ДНК-транспозоны в геноме человека,
по-видимому, замолчали навсегда. Судьба Alu, самых успешных клонизаторов
человеческого генома, напрямую зависит от успешности LINE1: если прекратится
размножение LINE1, то и Alu обречены на вымирание.
Короткие и длинные повторы ретропозонового типа занимают у человека большую долю
эухроматической части генома (46% у человека и 37% у мыши). Не из генов, а в
основном из ретропозонов сделан геном! В действительности же доля генома,
занимаемая диспергированными повторами, еще выше. Просто с течением времени в
повторах, ставших неактивными, накапливаются мутации, которых не замечает отбор
(нейтральные мутации), а уклонившиеся от своего прототипа более чем на 37%
повторы перестают распознаваться компьютерными программами. Скорость нейтральных
замен у человека оказалась примерно вдвое меньше, чем у мыши, видимо, потому что
время жизни одного поколения у человека по крайней мере в 20 раз больше, чем у
мыши.
Дальнейшее усовершенствование компьютерных программ для распознавания
ретропозоновых повторов, вероятно, покажет что роль их «ископаемых» копий в
организации и эволюции генома еще выше, чем кажется сейчас.
Следующее поколение биологов в значительной мере будет компьютерщиками, потому
что метод, лежащий в основе чтения генома, работа автоматического секвенатора,
требуют немедленной компьютерной обработки. Графическое выражение генома
человека, то есть карты всех хромосом с обозначенными на них распознанными
последовательностями читать очень сложно. Бумажный носитель не выдерживает
такого количества информации. Геномы живут в базах данных. В огромном количестве
полученной информации придется разбираться следующему поколению. Мы рассмотрим
только несколько важных закономерностей, вытекающих из компьютерного анализа
геномов.
Посмотрим, что представляет собой тот 1% генома, который кодирует белки. Из всех
предсказанных ORF, некоторые можно распознать и определить, какие белки они
кодируют. Биохимики умеют выделять эти белки. Им присвоены номенклатурные
названия. Оказалось, что поставить в соответствие определенному ORF конкретный
белок можно не более, чем в половине случаев. Около половины последовательностей
от 1% эухроматиновой части генома никто никогда не видел, и никакие функции им
присвоены быть не могут. И что означают продукты этих ORF — не известно. Хочу
обратить внимание на степень нашего невежества. Ведь подавляющее большинство
биологов занимается изучением именно структурных генов, имеющих выражение в
белке. Декларация их важности и разнообразии лежала в основе программы «Геном».
И за все время существования биохимии и молекулярной биологии только половину из
них удалось увидеть и как-то охарактеризовать. Поражает контраст между
вложениями в эту область молекулярной биологии и полученными результатами.
Кажется, что столь умеренный охват белковой части генома продиктован системой
финансирования науки, когда в каждом проекте автор обязан предложить будущее
использование еще не полученных результатов. Вряд ли такая система стимулирует
поиск чего-либо действительно нового, в частности нового белка.
На
повестке дня стоит упорядочение баз данных, по геному. В нашей лаборатории
начаты работы по приведению в порядок данных генома. Карты хромосом испещрены
квадратиками, условно обозначающими положение ORF, теоретически предсказанного
белка. Установление соответствия каждого квадратика какому-либо экспериментально
наблюдавшемуся белку называется аннотированием белка. Аннотирование открытых
рамок считывания (ORF) генома является одной из первоочередных задач.
Аннотирование требует знания молекулярной биологии и компьютерной грамотности.
Но работа эта очень скучная. Западные фирмы используют квалифицированный
персонал в России, где научные сотрудники готовы совмещать свою фактически
бесплатную, но интересную исследовательскую работу с оплачиваемым, но скучным
аннотированием. По ходу эксперимента исследователи проводят аннтоацию, и в
результате становятся эрудитами. Таким образом, и мы участвуем в международной
программе.
В
медицине давно сложилась иллюзия, что при наличии базового генома человека,
можно определить, чем отличается геном каждого конкретного человека. Допустим,
возможно прочесть геном новорожденного младенца. Тогда уже при рождении ему
выдадут паспорт о наличии каких-то мутаций, а значит и возможных болезнях,
являющихся фактором риска. Человеку от рождения будет прописана определенная
диета, строго выполняя которую, он сможет избежать предначертанную ему в геноме
судьбу.
Отличия генома одного человека от другого называются «точечные нуклеотидные
замены» (SNP — single nucleotide point mutation) — замена одной из букв в тексте
ДНК на другую. Для того, чтобы построить базовый геном человека, использовали
ДНК не менее 10 человек. Оказалось, что в геноме очень мало SNP — 1 замена на
1200 нуклеотидных пар. Более того, большая их часть попадает в такие области
генома, где они не будут иметь выражения в белке, эта область не транслируется.
Среди тех немногих, которые оказываются в области экзонов, то есть могли бы
как-то влиять на структуру белка, преобладают консервативные замены. Это
означает, что замена одного нуклеотида на другой не изменит название
аминокислоты, которую кодирует этот триплет. Правильная аминокислота окажется в
белке на нужном месте, несмотря на замену одного из нуклеотидов.
После
долгих исследований геронтологи тоже не нашли никакой корреляции между наборами
SNP в геномах и продолжительностью жизни. Выдать человеку генный паспорт,
который был бы одновременно и терапевтическим предписанием, нельзя. В средствах
массовой информации чрезвычайно популярна противоположная точка зрения. Дело в
том, что идея эта страшно привлекательна, на нее отпущены колоссальные деньги.
Даже очевидные, уже подтвержденные результаты программы «Геном человека» не
могут затормозить запущенную машину. Исследователи будут поддерживать иллюзию,
потому что от нее зависят рабочие места. Их нужно понять и простить. Идея
«генного паспорта» на данный момент представляется очень далекой от реальности.
Интерес фармацевтических фирм к кодирующей части генома оправдан. Для них не так
важно, что все белки, в том числе неизвестные, уже есть в базах данных, как ORF.
Важно то, что для многих заболеваний известны те белки, поломки которых за это
заболевание отвечают. Появляется возможность компьютерного моделирования свойств
необходимых лекарств. Органическая химия уже создала множество синтетических
соединений. Подобрать экспериментально соединение, действенное для связывания
определенного испорченного белка, ответственного за заболевание, — тяжелая и
долгая задача. Путь значительно сокращается, если на основании ORF ДНК
смоделировать белок, его третичную структуру (то, как он свертывается) и
провести компьютерное моделирование взаимодействия с множеством потенциально
связывающих его соединений. Результат компьютерного моделирования не будет
абсолютным, но может значительно сузить круг поиска. Появилась возможность
сначала лекарства смоделировать, а уже потом синтезировать или подобрать.
Тандемные повторы и морфогенез.
Успехи клонирования подтверждают тот факт, что в каждой клетке организма
содержится вся ДНК, необходимая для развития целого организма. Но клетки разных
тканей различаются по набору генов, которые в них работают. В клетках мышечной
ткани работают (экспрессированы) гены мышечных белков. В клетках кроветворного
ряда экспрессируются гены гемоглобина, а гены мышечных белков не работают
(репрессированы). Процесс приобретения клетками свойств, характерных для каждой
ткани, называется дифференцировкой. Принятая в настоящее время теория каскадной
регуляции работы генов, удовлетворительно объясняет то, как клетки приобретают
черты дифференцированных, но ничего не говорит о том, как клетки находят и
определяют свое место и как в результате организм приобретает определенную
форму.
История открытия и изучения нетранскрибируемой сателлитной ДНК насчитывает более
40 лет. Однако до сих пор функции тандемных повторов не очевидны. Предположение,
что при разворачивании хроматина некодирующая ДНК обеспечивает укладку остальной
части генома, неоднократно возникало в течение второй половины XX века, но до
сих пор оно не доказано. Современная формулировка этого предположения звучит
так. Происходящее при правильной ассоциации тандемных повторов пространственное
позиционирование активной ДНК приводит к формированию специфического паттерна
экспрессии, то есть продукт гена на хромосоме № 1 пойдет «направо» или «налево»
в зависимости от того, «прилипнет» ли поле сатДНК № 1 к такому же полю на
хромосоме № 9 или № 13.
Уже
появились свидетельства того, что в ядрах клеток одной ткани, допустим,
хромосома 1 предпочитает лежать рядом с хромосомой 9, а другой ткани — рядом с
хромосомой 13. Не зря же у них хромосомоспецифичные, но похожие друг на друга
центромеры.
К
сожалению, материала для проверки этой гипотезы результат чтения геномов таких
материалов не дает. Карты районов вокруг центромер и теломер хромосом
отсутствуют. Даже те немногие фрагменты хромосом с повторяющимися
последовательностями, которые прочтены, невозможно положить на карту хромосом —
их не за что «заякорить». А такие карты насущно необходимы, чтобы понять роль
некодирующей ДНК. Теперь, когда в результате чтения геномов стало ясно, что
подавляющая часть ДНК не кодирует, а, вероятно, выполняет архитектурную и
регуляторную роль, эта задача становится «горячей точкой» науки.
После
окончания деления клетки хромосомы разворачиваются в рабочее состояние, образуя
так называемые хромосомные территории. Их картируют с помощью
хромосомоспецифичных зондов. Возможность проследить сборку территории в
хромосому и наоборот, — разворачивание хромосомы в территорию, отсутствие
перемешивания материала хромосомных территорий между делениями клетки покончили
с бытовавшими в начале века представлениями о ядре клетки, как о
неструктурированном мешке, в котором навалом плавают нити хроматина. Никто не
сомневается ныне в том, что ядро структурировано не менее, чем цитоплазма клетки
с ее скелетными образованиями, и что хромосомы в ядре упакованы.
Последствия такой упаковки для регуляции генной экспрессии следующие. Постоянно
экспрессирующиеся гены расположены на периферии хромосомных территорий в больших
эухроматиновых петлях. Напротив, обедненные генами районы никогда не формируют
больших хроматиновых петель. Но центромерный район компактно расположен также на
периферии территории. Полагают, что в основании петель находятся
матрикс-ассоциированные районы (МАР), расположенные с периодичностью около
50—100 тысяч пар нуклеотидов вдоль ДНК. Среди МАР есть постоянные и временные.
Нетранскрибируемая ДНК представляет собой постоянные МАР, в то время как
временные МАР, расположенные в промоторных районах транскрибируемых структурных
генов, обеспечивают ассоциацию гена с макромолекулярным транскрипционным
комплексом по мере необходимости.
Создание трансгенных животных не имеет прямого отношения к программе «Геном», но
хорошо иллюстрирует ограничения догмы о том, что только имеющие выражение в
белке гены значимы и важны для жизнедеятельности. На белом свете живут прекрасно
мыши с геном гормона роста человека. Они бывают карликами или гигантами, но
остаются мышами. У мухи дрозофилы есть гены, которые могут заменить крыло на
ногу; но той же мухи дрозофилы. Никто никогда не вырастил у дрозофилы ногу мыши.
Существует трансгенный табак, который светится в темноте, потому что к нему
подсадили целую систему генов морской ночесветки, но на свету это обычное
растение табак. Трансгенные животные и растения свидетельствуют о том, что форму
организма гены вряд ли определяют. Легко можно получить трансгенное животное с
экспрессией чужого гена, но никто не родится, если в яйцеклетку ввести сатДНК
другого вида. Биологам придется напрячь свою изобретательность, чтобы подобрать
методические экспериментальные приемы изучения основ формообразования.
Очевидно, что развитие и морфогенез — детерминированный процесс. При
эмбриональном развитии все случается, как на параде. У всех икринок лягушки
одновременно, синхронно и одинаково направлено первое деление дробления, второе
и так далее. Каким-то образом эта программа должна быть записана в геноме. Но
места для ее записи пока никто не нашел.
Белки
Как
бы ни была важна роль ДНК, она не может функционировать сама по себе. В природе
не существует «голой» ДНК, она всегда покрыта белками. Неоднозначное и
недостаточное определение «жизнь — это форма существования белковых тел» тем не
менее содержит зерно истины. Для того, чтобы тандемные повторы вовлечь в
«домашнее хозяйство» клетки, должны существовать белки, которые избирательно с
ними связываются и, возможно, подтаскивают их друг к другу, ассоциируют, или
сообщают другим белкам, что дальше делать.
Коль
скоро повторы клонированы, биохимическими методами можно на клонированную
последовательность, как на крючок, выловить те белки, которые с максимальной
силой с нею связываются, а потом посмотреть, где эти белки расположены в ядре и
что они делают. В результате многолетней деятельности такого рода мы нашли
некоторые из этих белков. Случившаяся как раз в эти годы перестройка с одной
стороны сильно осложнила задачу — были годы, когда и клоны бактерий и научные
сотрудники погибали от бескормицы; с другой стороны — помогла: стала возможной
международная кооперация.
Теломер-связывающий белок по имени TRF2/МТВР выделили из оболочки ядра ооцита
(икринки, яйцеклетки) лягушки. Такая работа возможна только в России: вручную
выделили 10 тысяч ядер ооцитов, потом из них вручную выделили 10 тысяч оболочек
для того, чтобы стала возможна работа биохимическими методами. У белка двойное
название, потому что описали его одновременно англоязычные коллеги как TRF2 и
мы, как МТВР — мембранный теломер-связывающий белок. Потом переслали друг другу
препараты, сравнили и поняли, что это один и тот же белок. Теперь, после
идентификации и изучения локализации белка в разных клетках, мы точно знаем, что
всегда, когда теломеры прикреплены к мембране; это делает именно TRF2/МТВР
(рис.3).
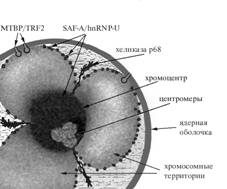
Рис.3.
Схема положения белков, принимающих участие в организации хромосомных
территорий.
Для
центромерных и прицентромерных сателлитных повторов разных классов специфичными
оказались два белка — хеликаза р68 и белок SAF-A/hnRNP-U (Рис.3). Для них не
понадобились новые названия. При поиске специфичного связывания с высокими
повторами невозможно открыть новые белки, потому что последовательности, с
которыми белки связываются, занимают не доли процентов, а целые проценты генома.
Следовательно, и белки, с ними связанные,— мажорные компоненты ядра, биохимики
их уже видели.
Оба
белка, которые мы выловили по их сильному связыванию с повторами сатДНК, уже
были известны как белки, участвующие в метаболизме РНК. Общими для них оказались
еще несколько свойств. При сильной специфичности связывания белки безразличны к
конкретной последовательности ДНК, но сильно чувствительны к степени ее
изогнутости. За счет структурно-специфичного связывания белки распознают сатДНК
с разной последовательностью, но одинаково изогнутые. Белки консервативны, то
есть почти одинаковы у человека и мыши, а связывают при этом видоспецифичные, то
есть отличные по последовательности сатДНК. Оба белка имеют АТФазный домен, то
есть потенциально могут быть моторными белками. Хеликаза, так же как TRF2/МТВР,
несет домен, позволяющий белку включаться в филаменты. SAF-A/hnRNP-U специфично
связывает не только сатДНК прицентромерного района, но и МАРы структурных генов
и участвует в транскрипции. Этот белок также оказался способен к кооперативному
связыванию: связывание двух молекул белка повышает шанс, что следующие также
свяжутся.
Гипотеза морфогенеза
Наша
рабочая гипотеза заключается в том, что программа морфогенеза записана в
видоспецифичных тандемных повторах. Можно пересадить почку конечности лягушки
цыпленку вместо будущего крыла. И она будет отвечать на все индукторы, на весь
каскад регуляций. Из лягушачьей почки ноги благополучно получится нога лягушки,
а не крыло цыпленка. И это означает, что не столько индукторы, которые лежат в
основе принятой сейчас теории каскадной регуляции развития, сколько реагирующая
система отвечает за форму. Самые первые этапы развития, когда клетки просто
быстро делятся, происходят без участия генов и в этот период в ядре и нет
гетерохроматиновых районов, состоящих из тандемных повторов класса сатДНК. А
когда начинается экспрессия первых генов, появляется и гетерохроматин.
Свойства тех белков, которые мы нашли, еще не дают возможность описать, как
происходит морфогенез, но позволяют начать понимать этот процесс. Для простоты,
махровые, как губки, хромосомные территории представим в виде шариков для
пинг-понга, а ядро в виде воздушного шара. Воздушный шар изнутри наполнен
пинг-понговыми шариками. Хромосомные территории собираются-разбираются при
каждом клеточном делении. Оболочка ядра при делениях также
собирается-разбирается на пузырьки. Первая точка хромосомы, приходящая в контакт
с пузырьками, на которые разбирается—собирается воздушный шар, т.е. мембрана
ядра, — это теломера. Теломер-связывающий белок TRF2/МТВР работает, как метка на
мембране и одновременно скрепка, которая прикрепляет теломеру. Это первая точка
не разрешает порядку хромосом нарушиться при митозе. Но хромосомы еще связаны в
кольцо нитью из тандемно повторенной ДНК между центромерами. А белковым
компонентом этой нити является наша хеликаза. Так система хромосом при делении
(метафазная пластина) становится жестко фиксированной. Но порядок хромосом в
метафазной пластине может оказаться необходимо поменять, что особенно важно во
время эмбриогенеза. Тогда АТФазные свойства хеликазы, которая не теряет связи с
центромерой и тогда, когда центромеры компактно лежат на периферии хромосомных
территорий, может помочь им сблизиться. Хеликаза может образовать филаменты,
прикрепленные к центромерам и сблизить их с помощью своего АТФазного мотора.
Свойства белка SAF-A/hnRNP-U помогут понять начало направленной
гетерохроматизации в эмбриогенезе. В раннем эмбриогенезе после первых быстрых
делений яйца наступает момент, когда клетки становится достаточно маленькими,
чтоб индуктор, запасенный в материнской цитоплазме стал действовать на ядро.
Определенный ген получает сигнал индуктора — экспрессируйся. Для того, чтобы
пошла транскрипция и экспрессия, на промоторе гена собирается транскрипционный
комплекс и его МАР оказывается прикреплен, что вызывает каскадную реакцию с
присоединением других молекул белка и тандемных повторов сатДНК. Таким образом
происходит направленная гетерохроматизация, зависящая в каждом ядре от того,
какой именно ген под влиянием какого индуктора включился. МАР-связывающие белки
при деленииостаются в составе внешнего слоя хромосомы и, таким образом,
приобретенные метки наследуются. За счет подобных белков достигается
необратимость развития и именно с такого рода метками на ДНК связаны трудности
клонирования.
Изучение белков, специфичных для повторяющихся последовательностей, еще только
начинается. Те белки, которые нам удалось идентифицировать, скорее всего
являются представителями целого класса белков. Их свойства заставляют
предполагать существование отличного от классического трехбуквенного
генетического кода, структурного кода, который определяет варианты укладки ДНК.
Заключение
Расхожим сравнением является сравнение генома с текстом из четырех букв,
разделенным на тома —хромосомы. До сих пор содержательным текстом этого издания
считали только кодирующие гены. Однако трудно представить, что природа позволит
геному на 99% состоять из бессмысленной ДНК. Жизнь — это процесс, идущий в
условиях постоянного дефицита энергии. Жизнь балансирует в узкой области между
запретами различных физических констант. Это явление макромира, и только
синергетика (термодинамика неравновесных процессов) спасла физические основы
жизни от кошмара второго начала термодинамики. И вряд ли жизнь может позволить
себе много лишнего, особенно в управляющем аппарате клетки — ядре и ДНК. Если
продолжать аналогию с текстом на бумажном носителе, тандемные повторы можно
сравнить с бумажным носителем, ответственным за форму книги, а диспергированные
повторы — со знаками препинания. Но если принять, что тандемные повторы — это
бумага, на которой написан текст, то ее можно не только разрезать на страницы,
но и свернуть в конус или трубочку, склеить углы, и даже сложить оригами, с
формой зависящей от того, каким образом захотят склеиваться разные части листа —
разные хромосомоспецифичные тандемные повторы. Экономная эволюция писала свои
тексты на носителе, активно участвующем в чтении самого текста и, следовательно,
до определенной степени также являющегося текстом.
Очевидно, что методов, уже использованных при чтении геномов, недостаточно для
изучения этого динамичного носителя. Мало прочесть «белые пятна» генома, нужны
методы манипулирования огромными массивами ДНК. А для этого необходима смена
догмы: перестать мыслить основную часть генома как «помойную» ДНК (junk DNA).
Точное количественное выражение степени «непомойности» повторяющейся ДНК
является одним из основных положительных итогов программы «Геном».
Литература
1. Lander et al.
International Human Genome Sequencing Consortium. 2001. Initial sequencing and
analysis of the human genome. Nature. 15, 409 (6822): 860—921.
2. Venter C.J., Adams M.D.,
Myers E.W. et al. 2001. The sequence of the human genome. Science. 291:
1304—1351.
3. Waterston R.H. et al. Mouse
Genome Sequencing Consortium. 2002. Initial sequencing and comparative analysis
of the mouse genome. Nature. 420
(6915): 520—562.
4. Физики шутят-2
Глоссарий
Ген
— единица наследственного материала, ответственная за формирование какого-либо
элементарного признака; как правило кодирует белок. Гены физически существуют
как участки молекул нуклеиновых кислот с определенной последовательностью
нуклеотидов.
Геном — совокупность всей
наследственной информации, физически существующая в виде молекул нуклеиновых
кислот.
Генетический код — система записи
наследственной информации в молекулах нуклеиновых кислот; определяет порядок
включения аминокислот в молекулу белка. Единицей кода служит кодон, или
триплет,— последовательность из трех нуклеотидных звеньев: три нуклеотида
кодируют одну аминокислоту.
Гетерохроматин — часть
хроматина, сохраняющая компактную структуру после разворачивания хромосом.
ДНК
-(дезоксирибонуклеиновая кислота) — биологический полимер, носитель
наследственности у большинства живых существ. Состоит из чередующихся остатков
четырех азотистых оснований или нуклеотидов.
Клонирование ДНК — выделение
конкретных фрагментов ДНК и размножение их в бактериях или дрожжах.
Секвенирование — определение
последовательности чередования нуклеотидов в этих фрагментах.
Матрикс-ассоциированные районы (МАР)
— участки ДНК в регуляторных областях или в интронах генов, ответственные за
прикрепление работающего гена к транскрипционному комплексу белков.
Метод — способ деления ядер
клеток, обеспечивающий тождественное распределение генетического материала между
дочерними клетками.
Открытые рамки считывания (ORF,
open reading frames) — участки генома, с которых теоретически может получиться
белок.
Протеом — полный набор белков,
кодируемый геномом.
Синтеничные районы — участки
геномов разных видов, в которых расположение генов одинаково.
Сплайсинг — процесс вырезания
интронов из молекул РНК и сшивания экзонов.
Теломеры — концевые сегменты
хромосомы.
Трансляция — процесс синтеза
белка на матрице РНК; последовательность нуклеотидов РНК в соответствии с
генетическим кодом «переводится» в последовательность аминокислотных остатков в
молекуле белка.
Транскрипция — процесс синтеза молекул РНК на ДНК
Хромосома — структуры из конденсированной линейной ДНК, покрытой белками, на
которые разделяется хроматин при делении клетки.
Хроматин — в промежутках между делениями клетки - нити ДНК,
покрытые белками.
Центромера (первичная перетяжка) — участок хромосомы, удерживающий
вместе две её нити (хроматиды) и играющий основную роль в расхождении их при
делении клетки.
Экзоны
— участки гена, имеющие выражение в белке. В гене экзоны разделены
некодирующими участками — интронами. При транскрипции гена экзоны и
интроны считываются вместе как одна большая молекула РНК.
Экспрессия генов — реализация
генетической информации в белке.
Эухроматин — часть хроматина, которая содержит большинство генов.
|